1. Input Embeddings
The InputEmbedding class below is responsible for converting the input text into numerical vectors of d_model dimensions. ==To prevent that our input embeddings become extremely small, we normalize them by multiplying them by the== ==√𝑑_𝑚𝑜𝑑𝑒𝑙==
In the image below, we can see how the embeddings are created. First, we have a sentence that gets split into tokens — we will explore what tokens are later on — . Then, the token IDs — identification numbers — are transformed into the embeddings, which are high-dimensional vectors.
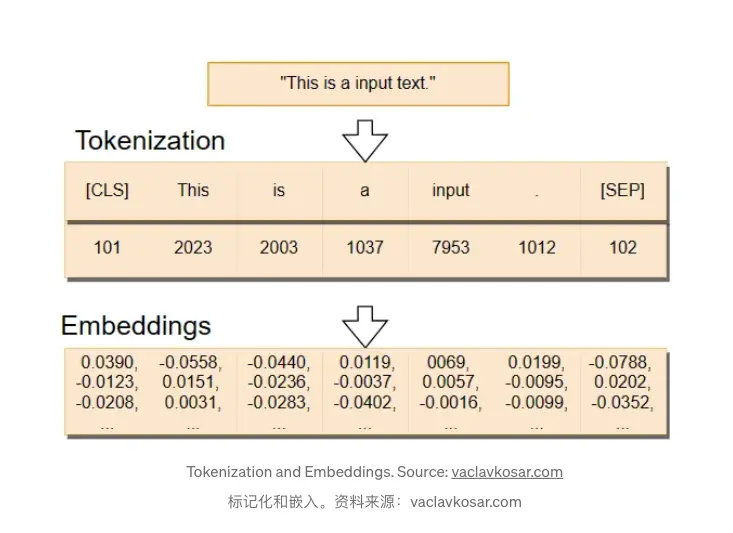
1.1 Tokenization:
- Tokenization is cutting input data into parts (symbols) that can be mapped (embedded) into a vector space.
- For example, input text is split into frequent words e.g. transformer tokenization.
- Sometimes we append special tokens to the sequence e.g. class token ([CLS]) used for classification embedding in BERT transformer.
- Tokens are mapped to vectors (embedded, represented), which are passed into neural neural networks.
- Token sequence position itself is often vectorized and added to the word embeddings (positional encodings).
1.2 Embedding:
Embedding is a task specific lower dimensional vector representation of data like a word, image, document, or an user.
- Want to represent data as numbers to compute our tasks.
- Start with simple high dimensional feature vectors created from input data e.g. vocabulary word index.
- Then find lower dimensional vectors optimized for our task called embeddings.
- Can train with both unsupervised, and supervised tasks:
- Before representing the full data we often split data into meaningful parts called tokens.
Input Tokenization:
- Tokenization is cutting input data into parts (symbols) that can be mapped (embedded) into a vector space.
标记化是将输入数据切割成可以映射(嵌入)到向量空间中的部分(符号)。 - For example, input text is split into frequent words e.g. transformer tokenization.
例如,输入文本被分成频繁出现的单词,例如变压器标记化。 - Sometimes we append special tokens to the sequence e.g. class token ([CLS]) used for classification embedding in BERT transformer.
有时我们会在序列中附加特殊标记,例如类标记([CLS])用于 BERT 转换器中的分类嵌入。 - Tokens are mapped to vectors (embedded, represented), which are passed into neural neural networks.
标记被映射到向量(嵌入的、表示的),这些向量被传递到神经网络中。 - Token sequence position itself is often vectorized and added to the word embeddings (positional encodings).
标记序列位置本身通常被向量化并添加到单词嵌入(位置编码)中。
Embedding Tokens:
- Map Tokens to their representations e.g. word (token) embeddings, image patch (token) embeddings.
- Step by step pool the sequences of embeddings into shorter sequences, until we get a single full contextual data representation for the output.
- Can pool via averaging, summation, segmentation, or just take a single sequence position output embedding (class token).
Simple Document Representations:
- Once were paper archives replaced with databases of textual documents some tasks became cheaper: search by list of words (query) ~1970s, finding document topics ~1980
- simplest methods: counting word occurrences on documents level into sparce matrices as feature vectors in methods term frequency–inverse document frequency (TF-IDF), Latent semantic analysis (LSA)
- LSA:Latent Semantic Analysis (LSA) is a technique in natural language processing that analyzes relationships between a set of documents and the terms they contain. It works by constructing a term-document matrix and then applying singular value decomposition (SVD) to reduce dimensionality. This process uncovers latent structures in the data, helping to identify patterns and relationships between terms and concepts.
- this co-occurrence of words in documents later used to embed words
Non-Contextual Words Vectors:
- document split into sentence sized running window of 10 words.
- each of 10k sparsely coded vocabulary words is mapped to a vector (embedded) into a 300 dimensional space.
- the embeddings are compressed as only 300 dimensions much less than 10k vocabulary feature vectors.
- the embeddings are dense as the vector norm is not allowed to grow too large
- these word vectors are non-contextual (global), so we cannot disambiguate fruit (flowering) from fruit (food)
Word2Vec Method for Non-contextual Word Vectors
- Word2vec (Mikolov 2013) trains the middle-word vector to be close to sum of 10 surrounding words embeddings.
- Even simpler method is GloVe (Pennington 2014), which counts co-occurrences in a 10 word window, then reduces dimensionality with SVD.
- Other similar methods are FastText, StarSpace.
- Words appearing in similar contexts have similar Word2vec embedding vectors. Word meaning disambiguation is not possible.
- Vector manipulation leads to meaning manipulation, e.g., vector operation
v(king) – v(man) + v(woman)returns a vector close tov(queen).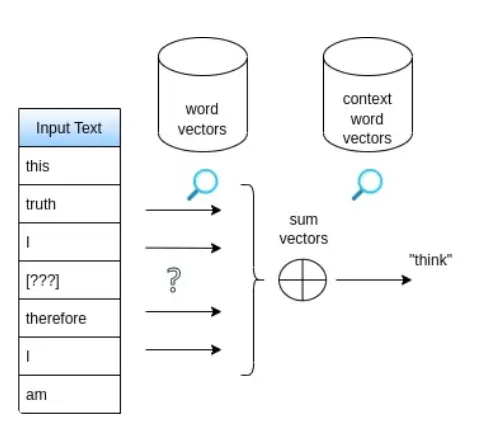
Knowledge Graph’s Nodes Are Disambiguated
- knowledge graph (KG) e.g. Wikidata: each node is specific fruit (flowering) vs fruit (food)
知识图(KG)例如维基数据:每个节点都是特定的水果(开花)与水果(食物) - KG is a tradeoff between database and training data samples
KG是数据库和训练数据样本之间的权衡 - Wikipedia and the internet are something between knowledge graph and set of documents
维基百科和互联网介于知识图谱和文档集之间 - random walks over KG are valid “sentences”, which can be used to train node embeddings e.g. with Word2vec (see “link prediction”)
KG 上的随机游走是有效的“句子”,可用于训练节点嵌入,例如使用 Word2vec(参见“链接预测”)
Contextual Word Vectors with Transformer
使用 Transformer 的上下文词向量
- imagine there is a node for each specific meaning of each word in hypothetical knowledge graph
假设假设的知识图中每个单词的每个特定含义都有一个节点 - given a word in a text of 100s of words, the specific surrounding words locate our position within the knowledge graph, and identify the word’s meaning
给定数百个单词的文本中的一个单词,特定的周围单词定位我们在知识图谱中的位置,并识别该单词的含义 - two popular model architectures incorporate context:
两种流行的模型架构包含上下文:- recurrent neural networks (LSTM, GRU) are sequential models with memory units
循环神经网络(LSTM、GRU)是具有记忆单元的顺序模型 - transformer architecture consumes the entire input sequence is State-of-the-art 2022
Transformer 架构消耗了整个输入序列,是 2022 年最先进的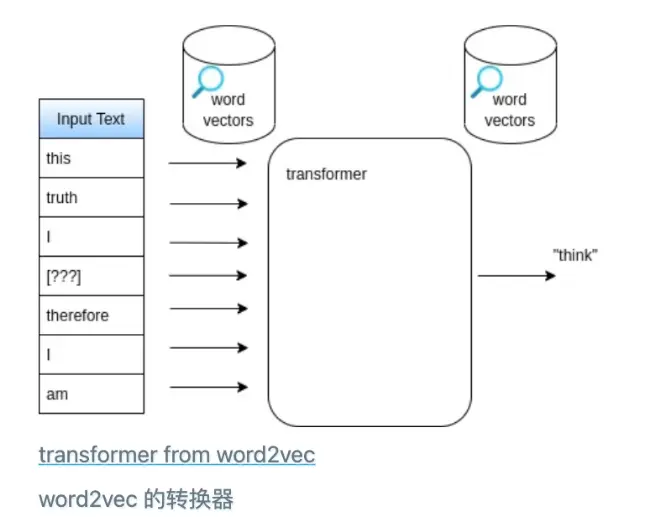
- recurrent neural networks (LSTM, GRU) are sequential models with memory units
Image Embeddings 图像嵌入
- instead of tokens (words) we embed image patches
我们嵌入图像补丁而不是标记(单词) - convolutional networks embed overlapping patches and progressively pool them into a single image embedding
卷积网络嵌入重叠的补丁并逐渐将它们汇集到单个图像嵌入中 - Vision Transformer (ViT) uses transformer architecture and the output class token embedding is used as an image embedding
Vision Transformer (ViT) 使用 Transformer 架构,输出类 token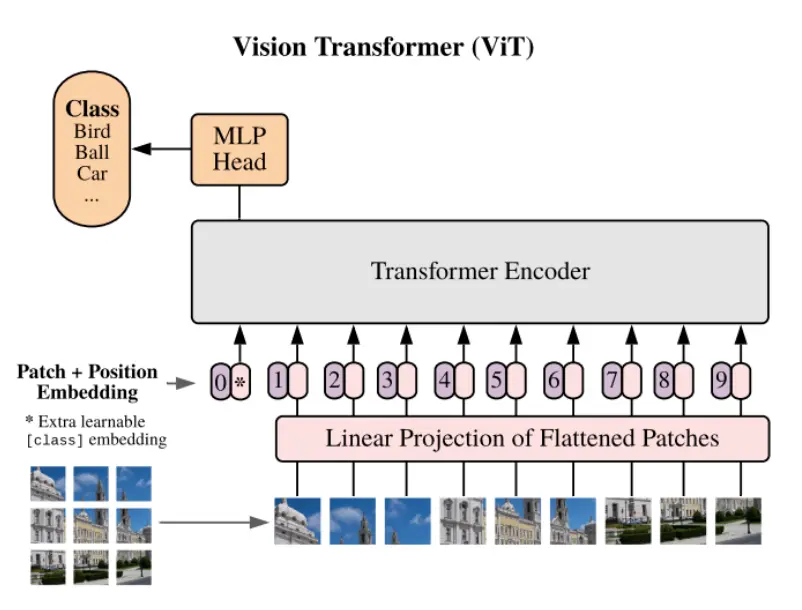 嵌入用作图像嵌入
嵌入用作图像嵌入
Reusing Embeddings 重用嵌入
- Embeddings are trained to represent data such that it makes the training task easy
嵌入经过训练来表示数据,从而使训练任务变得容易 - Embeddings perform often better than the input feature vectors on at least related tasks
嵌入至少在相关任务上通常比输入特征向量表现更好 - some tasks are more related than others: multi-task learning
有些任务比其他任务更相关:多任务学习 - speculation: Because of high number precision, smoothness of the neural network layers, and random weight initialization, most input information is preserved within the output embeddings
推测:由于数字精度高、神经网络层平滑以及随机权重初始化,大多数输入信息都保留在输出嵌入中- that would explain why neural networks can improve by training
这可以解释为什么神经网络可以通过训练来改进
- that would explain why neural networks can improve by training
- for example Word2vec or BERT embeddings are trained on a word prediction tasks, but their embeddings are useful for e.g. text classification tasks
例如,Word2vec 或 BERT 嵌入是在单词预测任务上进行训练的,但它们的嵌入对于例如文本分类任务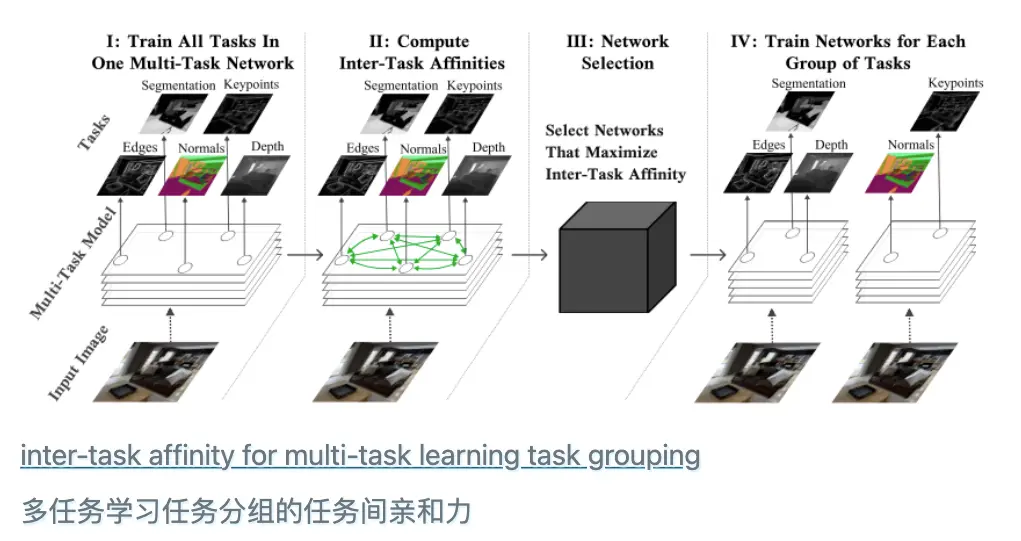
# Importing libraries
# PyTorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split
from torch.utils.tensorboard import SummaryWriter
# Math
import math
# HuggingFace libraries
from datasets import load_dataset
from tokenizers import Tokenizer
from tokenizers.models import WordLevel
from tokenizers.trainers import WordLevelTrainer
from tokenizers.pre_tokenizers import Whitespace
# Pathlib
from pathlib import Path
# typing
from typing import Any
# Library for progress bars in loops
from tqdm import tqdm
# Importing library of warnings
import warnings
# Creating Input Embeddings
class InputEmbeddings(nn.Module):
def __init__(self,d_model:int,vocab_size:int):
super().__init__()
self.d_model = d_model # Dimension of vectors (512)
self.vocab_size = vocab_size # Size of the vocabulary
# PyTorch layer that converts integer indices to dense embeddings
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self,x):
# Normalizing the variance of the embeddings
return self.embedding(x) * math.sqrt(self.d_model)
Positional Encoding
In the original paper, the authors add the positional encodings to the input embeddings at the bottom of both the encoder and decoder blocks so the model can have some information about the relative or absolute position of the tokens in the sequence. The positional encodings have the same dimension 𝑑_model the embeddings, so that the two vectors can be summed and we can combine the semantic content from the word embeddings and positional information from the positional encodings.
# Creating the Positional Encoding
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, seq_len: int, dropout: float) -> None:
super().__init__()
self.d_model = d_model # Dimensionality of the model
self.seq_len = seq_len # Maximum sequence length
self.dropout = nn.Dropout(dropout) # Dropout layer to prevent overfitting
# Creating a positional encoding matrix of shape (seq_len, d_model) filled with zeros
pe = torch.zeros(seq_len, d_model)
# Creating a tensor representing positions (0 to seq_len - 1)
position = torch.arange(0, seq_len, dtype = torch.float).unsqueeze(1) # Transforming 'position' into a 2D tensor['seq_len, 1']
# Creating the division term for the positional encoding formula
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# Apply sine to even indices in pe
pe[:, 0::2] = torch.sin(position * div_term)
# Apply cosine to odd indices in pe
pe[:, 1::2] = torch.cos(position * div_term)
# Adding an extra dimension at the beginning of pe matrix for batch handling
pe = pe.unsqueeze(0)
# Registering 'pe' as buffer. Buffer is a tensor not considered as a model parameter
self.register_buffer('pe', pe)
def forward(self,x):
# Addind positional encoding to the input tensor X
x = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False)
return self.dropout(x) # Dropout for regularization
Layer Normalization:
从单个训练样本上的层中所有神经元的输入总和计算用于规范化的均值和方差,将批量规范化转化为层规范化 计算同一个样本的所有特征的均值和方差。 $$ \mu_l = \frac{1}{d} \sum_{i=1}^{d} x_i \quad (1) $$
$$ \sigma_l^2 = \frac{1}{d} \sum_{i=1}^{d} (x_i - \mu_l)^2 \quad (2) $$
$$ \hat{x}_i = \frac{x_i - \mu_l}{\sqrt{\sigma_l^2}} \quad (3) $$
或
$$ \hat{x}_i = \frac{x_i - \mu_l}{\sqrt{\sigma_l^2 + \epsilon}} \quad (3) $$
添加 $$\epsilon$$有助于当 $\sigma_l^2$ 很小时,避免分母为0。
$$ y_i = \mathcal{LN}(x_i) = \gamma \cdot \hat{x}_i + \beta \quad (4) $$
# Creating Layer Normalization
class LayerNormalization(nn.Module):
def __init__(self, eps: float = 10**-6) -> None: # We define epsilon as 0.000001 to avoid division by zero
super().__init__()
self.eps = eps
# We define alpha as a trainable parameter and initialize it with ones
self.alpha = nn.Parameter(torch.ones(1)) # One-dimensional tensor that will be used to scale the input data
# We define bias as a trainable parameter and initialize it with zeros
self.bias = nn.Parameter(torch.zeros(1)) # One-dimensional tenso that will be added to the input data
def forward(self, x):
mean = x.mean(dim = -1, keepdim = True) # Computing the mean of the input data. Keeping the number of dimensions unchanged
std = x.std(dim = -1, keepdim = True) # Computing the standard deviation of the input data. Keeping the number of dimensions unchanged
# Returning the normalized input
return self.alpha * (x-mean) / (std + self.eps) + self.bias
Feed-Forward Network
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between. $$FFN(x) = max(0, xW1 + b1)W2 + b2$$ While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is $$d_{model}=512$$ and the inner-layer has dimensionality $$d_{ff} = 2048$$
# Creating Feed Forward Layers
class FeedForwardBlock(nn.Module):
def __init__(self,d_model:int,d_ff:int,dropout:float) -> None:
super().__init__()
# First linear transformation
self.linear_1 = nn.Linear(d_model, d_ff) # W1 & b1
self.dropout = nn.Dropout(dropout) # Dropout to prevent overfitting
# Second linear transformation
self.linear_2 = nn.Linear(d_ff, d_model) # W2 & b2
def forward(self, x):
# (Batch, seq_len, d_model) --> (batch, seq_len, d_ff) -->(batch, seq_len, d_model)
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))
Multi-Head Attention
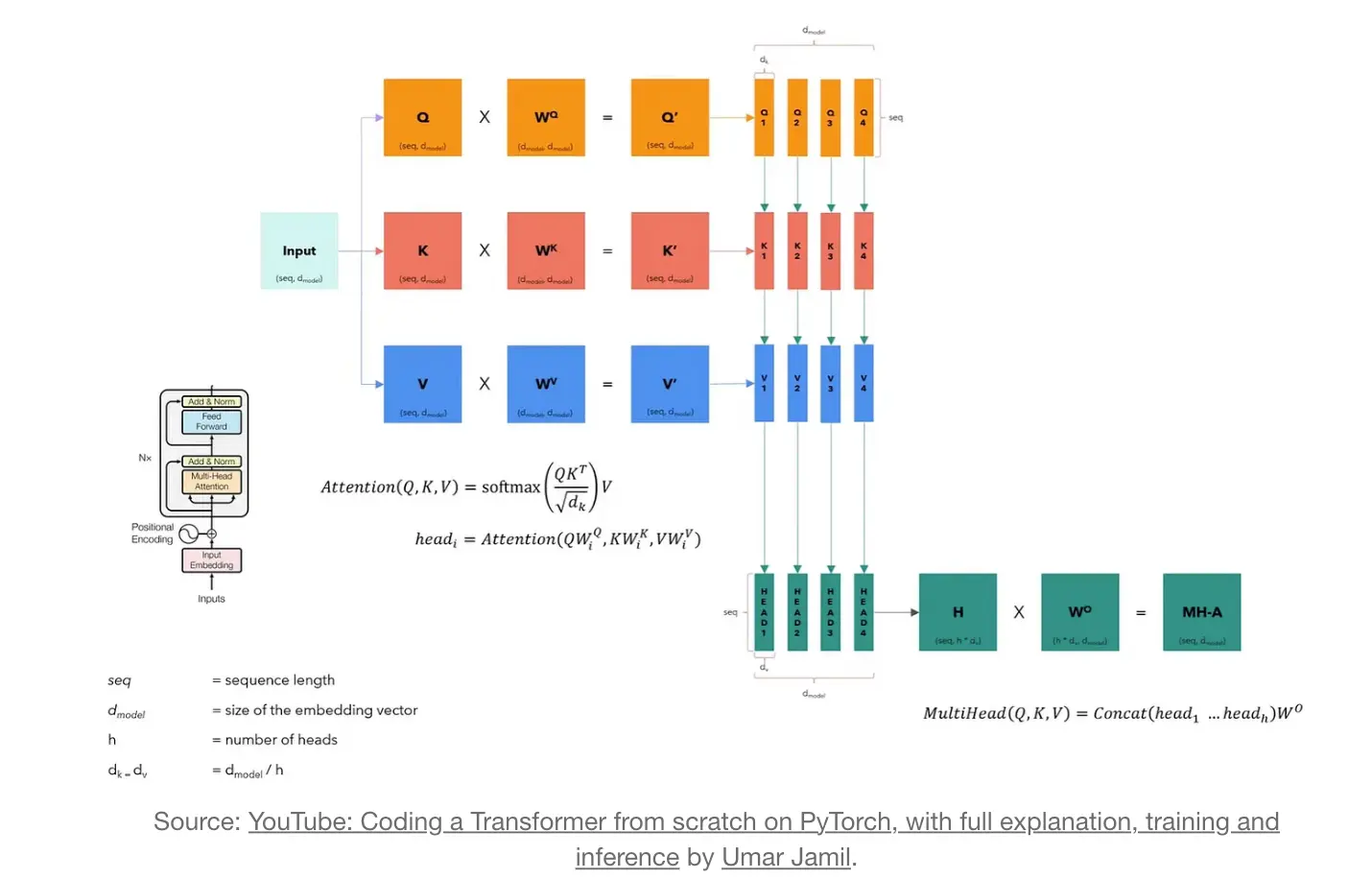
# Creating the Multi-Head Attention block
class MultiHeadAttentionBlock(nn.Module):
def __init__(self, d_model: int, h: int, dropout: float) -> None:
# h = number of heads
super().__init__()
self.d_model = d_model
self.h = h
# We ensure that the dimensions of the model is divisible by the number of heads
assert d_model % h == 0, 'd_model is not divisible by h'
# d_k is the dimension of each attention head's key, query, and value vectors
self.d_k = d_model // h #d_k formula,like in the original "Attention Is All You Need"
# Defining the weight matrices
self.w_q = nn.Linear(d_model, d_model) # W_q
self.w_k = nn.Linear(d_model, d_model) # W_k
self.w_v = nn.Linear(d_model, d_model) # W_v
self.w_o = nn.Linear(d_model, d_model) # W_o
self.dropout = nn.Dropout(dropout) # Dropout layer to avoid overfitting
@staticmethod
def attention(query, key, value, mask, dropout: nn.Dropout):
# mask => When we want certain words to NOT interact with others, we "hide" them
d_k = query.shape[-1] # The last dimension of query, key, and value
# We calculate the Attention(Q,K,V) as in the formula in the image above
# @ = Matrix multiplication sign in PyTorch
attention_scores = (query @ key.transpose(-2,-1)) / math.sqrt(d_k)
# Before applying the softmax, we apply the mask to hide some interactions between words
if mask is not None: # If a mask IS defined...
# Replace each value where mask is equal to 0 by -1e9
attention_scores.masked_fill_(mask == 0, -1e9)
attention_scores = attention_scores.softmax(dim = -1) # Applying softmax
if dropout is not None:
# If a dropout IS defined...
# We apply dropout to prevent overfitting
attention_scores = dropout(attention_scores)
# Multiply the output matrix by the V matrix, as in the formula
return (attention_scores @ value), attention_scores
def forward(self, q, k, v, mask):
query = self.w_q(q) # Q' matrix
key = self.w_k(k) # K' matrix
value = self.w_v(v) # V' matrix
# Splitting results into smaller matrices for the different heads
# Splitting embeddings (third dimension) into h parts
# Transpose => bring the head to the second dimension
query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1,2)
# Transpose => bring the head to the second dimension
key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1,2)
# Transpose => bring the head to the second dimension
value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1,2)
# Obtaining the output and the attention scores
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, mask, self.dropout)
# Obtaining the H matrix
x = x.transpose(1, 2).contiguous().view(x.shape[0], -1, self.h * self.d_k)
return self.w_o(x) # Multiply the H matrix by the weight matrix W_o, resulting in the MH-A matrix
Residual Connection:
# Building Residual Connection
class ResidualConnection(nn.Module):
def __init__(self, dropout: float) -> None:
super().__init__()
self.dropout = nn.Dropout(dropout) # We use a dropout layer to prevent overfitting
self.norm = LayerNormalization() # We use a normalization layer
def forward(self, x, sublayer):
# We normalize the input and add it to the original input 'x'. This creates the residual connection process.
return x + self.dropout(sublayer(self.norm(x)))
EncoderBlock:
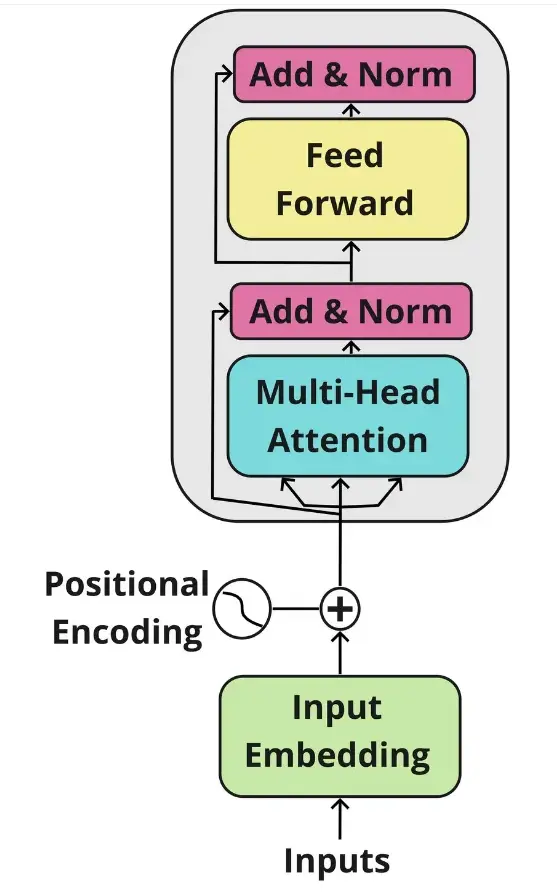
# Building Encoder Block
class EncoderBlock(nn.Module):
# This block takes in the MultiHeadAttentionBlock and FeedForwardBlock, as well as the dropout rate for the residual connections
def __init__(self, self_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
# Storing the self-attention block and feed-forward block
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(2)])
# 2 Residual Connections with dropout
def forward(self, x, src_mask):
# Applying the first residual connection with the self-attention block
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask))
# Three 'x's corresponding to query, key, and value inputs plus source mask
# Applying the second residual connection with the feed-forward block
x = self.residual_connections[1](x, self.feed_forward_block)
return x # Output tensor after applying self-attention and feed-forward layers with residual connections.
# Building Encoder
# An Encoder can have several Encoder Blocks
class Encoder(nn.Module):
# The Encoder takes in instances of 'EncoderBlock'
def __init__(self, layers: nn.ModuleList) -> None:
super().__init__()
self.layers = layers # Storing the EncoderBlocks
self.norm = LayerNormalization() # Layer for the normalization of the output of the encoder layers
def forward(self, x, mask):
# Iterating over each EncoderBlock stored in self.layers
for layer in self.layers:
x = layer(x, mask) # Applying each EncoderBlock to the input tensor 'x'
return self.norm(x) # Normalizing output
Decoder:
We will start by building the DecoderBlock class, and then we will build the Decoder class, which will assemble multiple DecoderBlocks.
# Building Decoder Block
class DecoderBlock(nn.Module):
# The DecoderBlock takes in two MultiHeadAttentionBlock. One is self-attention, while the other is cross-attention.
# It also takes in the feed-forward block and the dropout rate
def __init__(self, self_attention_block: MultiHeadAttentionBlock, cross_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(3)])
# List of three Residual Connections with dropout rate
def forward(self, x, encoder_output, src_mask, tgt_mask):
# Self-Attention block with query, key, and value plus the target language mask
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tgt_mask))
# The Cross-Attention block using two 'encoder_ouput's for key and value plus the source language mask. It also takes in 'x' for Decoder queries
x = self.residual_connections[1](x, lambda x: self.cross_attention_block(x, encoder_output, encoder_output, src_mask))
# Feed-forward block with residual connections
x = self.residual_connections[2](x, self.feed_forward_block)
return x
# Building Decoder
# A Decoder can have several Decoder Blocks
class Decoder(nn.Module):
# The Decoder takes in instances of 'DecoderBlock'
def __init__(self, layers: nn.ModuleList) -> None:
super().__init__()
# Storing the 'DecoderBlock's
self.layers = layers
self.norm = LayerNormalization() # Layer to normalize the output
def forward(self, x, encoder_output, src_mask, tgt_mask):
# Iterating over each DecoderBlock stored in self.layers
for layer in self.layers:
# Applies each DecoderBlock to the input 'x' plus the encoder output and source and target masks
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.norm(x) # Returns normalized output
The ProjectionLayer class below is responsible for converting the output of the model into a probability distribution over the vocabulary, where we select each output token from a vocabulary of possible tokens.
# Buiding Linear Layer
class ProjectionLayer(nn.Module):
def __init__(self, d_model: int, vocab_size: int) -> None: # Model dimension and the size of the output vocabulary
super().__init__()
self.proj = nn.Linear(d_model, vocab_size) # Linear layer for projecting the feature space of 'd_model' to the output space of 'vocab_size'
def forward(self, x):
return torch.log_softmax(self.proj(x), dim = -1) # Applying the log Softmax function to the output
Building the Transformer:
# Creating the Transformer Architecture
class Transformer(nn.Module):
# This takes in the encoder and decoder, as well the embeddings for the source and target language.
# It also takes in the Positional Encoding for the source and target language, as well as the projection layer
def __init__(self, encoder: Encoder, decoder: Decoder, src_embed: InputEmbeddings, tgt_embed: InputEmbeddings, src_pos: PositionalEncoding, tgt_pos: PositionalEncoding, projection_layer: ProjectionLayer) -> None:
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
# Encoder
def encode(self, src, src_mask):
src = self.src_embed(src) # Applying source embeddings to the input source language
src = self.src_pos(src) # Applying source positional encoding to the source embeddings
return self.encoder(src, src_mask) # Returning the source embeddings plus a source mask to prevent attention to certain elements
# Decoder
def decode(self, encoder_output, src_mask, tgt, tgt_mask):
tgt = self.tgt_embed(tgt) # Applying target embeddings to the input target language (tgt)
tgt = self.tgt_pos(tgt) # Applying target positional encoding to the target embeddings
# Returning the target embeddings, the output of the encoder, and both source and target masks
# The target mask ensures that the model won't 'see' future elements of the sequence
return self.decoder(tgt, encoder_output, src_mask, tgt_mask)
# Applying Projection Layer with the Softmax function to the Decoder output
def project(self, x):
return self.projection_layer(x)
We will set the same parameters as in the original paper, Attention Is All You Need, where 𝑑_𝑚𝑜𝑑𝑒𝑙 = 512, 𝑁 = 6, ℎ = 8, dropout rate 𝑃_𝑑𝑟𝑜𝑝 = 0.1, and 𝑑_𝑓𝑓= 2048.
# Building & Initializing Transformer
# Definin function and its parameter, including model dimension, number of encoder and decoder stacks, heads, etc.
def build_transformer(src_vocab_size: int, tgt_vocab_size: int, src_seq_len: int, tgt_seq_len: int, d_model: int = 512, N: int = 6, h: int = 8, dropout: float = 0.1, d_ff: int = 2048) -> Transformer:
# Creating Embedding layers
src_embed = InputEmbeddings(d_model, src_vocab_size) # Source language (Source Vocabulary to 512-dimensional vectors)
tgt_embed = InputEmbeddings(d_model, tgt_vocab_size) # Target language (Target Vocabulary to 512-dimensional vectors)
# Creating Positional Encoding layers
src_pos = PositionalEncoding(d_model, src_seq_len, dropout) # Positional encoding for the source language embeddings
tgt_pos = PositionalEncoding(d_model, tgt_seq_len, dropout) # Positional encoding for the target language embeddings
# Creating EncoderBlocks
encoder_blocks = [] # Initial list of empty EncoderBlocks
for _ in range(N): # Iterating 'N' times to create 'N' EncoderBlocks (N = 6)
encoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout) # Self-Attention
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout) # FeedForward
# Combine layers into an EncoderBlock
encoder_block = EncoderBlock(encoder_self_attention_block, feed_forward_block, dropout)
encoder_blocks.append(encoder_block) # Appending EncoderBlock to the list of EncoderBlocks
# Creating DecoderBlocks
decoder_blocks = [] # Initial list of empty DecoderBlocks
for _ in range(N): # Iterating 'N' times to create 'N' DecoderBlocks (N = 6)
decoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout) # Self-Attention
decoder_cross_attention_block = MultiHeadAttentionBlock(d_model, h, dropout) # Cross-Attention
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout) # FeedForward
# Combining layers into a DecoderBlock
decoder_block = DecoderBlock(decoder_self_attention_block, decoder_cross_attention_block, feed_forward_block, dropout)
decoder_blocks.append(decoder_block) # Appending DecoderBlock to the list of DecoderBlocks
# Creating the Encoder and Decoder by using the EncoderBlocks and DecoderBlocks lists
encoder = Encoder(nn.ModuleList(encoder_blocks))
decoder = Decoder(nn.ModuleList(decoder_blocks))
# Creating projection layer
projection_layer = ProjectionLayer(d_model, tgt_vocab_size) # Map the output of Decoder to the Target Vocabulary Space
# Creating the transformer by combining everything above
transformer = Transformer(encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer)
# Initialize the parameters
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return transformer # Assembled and initialized Transformer. Ready to be trained and validated!
Tokenizer:
# Defining Tokenizer
def build_tokenizer(config, ds, lang):
# Crating a file path for the tokenizer
tokenizer_path = Path(config['tokenizer_file'].format(lang))
# Checking if Tokenizer already exists
if not Path.exists(tokenizer_path):
# If it doesn't exist, we create a new one
tokenizer = Tokenizer(WordLevel(unk_token = '[UNK]')) # Initializing a new world-level tokenizer
tokenizer.pre_tokenizer = Whitespace() # We will split the text into tokens based on whitespace
# Creating a trainer for the new tokenizer
trainer = WordLevelTrainer(special_tokens = ["[UNK]", "[PAD]","[SOS]", "[EOS]"], min_frequency = 2) # Defining Word Level strategy and special tokens
# Training new tokenizer on sentences from the dataset and language specified
tokenizer.train_from_iterator(get_all_sentences(ds, lang), trainer = trainer)
tokenizer.save(str(tokenizer_path))#Saving trained tokenizer to the file path specified at the beginning of the function
else:
tokenizer = Tokenizer.from_file(str(tokenizer_path)) # If the tokenizer already exist, we load it
return tokenizer # Returns the loaded tokenizer or the trained tokenizer
参考博客:https://github.com/hkproj/pytorch-transformer
下一步学习:# FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning